 Home Page
Home Page Credo pages
Credo pages Genealogy
Genealogy Eteocretan language
Eteocretan language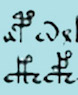 Glosso-poeia
Glosso-poeia "The
"TheBrx ['puɺaçi] (Pulashi) Syllabary:
its phonology and orthography
1. Introduction
- 1.1 The symbols
- The considerations in designing this syllabary were:
- 1. Words need to be as short as possible, therefore morphemes should consist of no more than three letters at the most.
- 2. Use should be made not only of one vowel morphemes but also morphemes written with one consonant.
- 4. Each letter should denote only one basic sound.
- 5. There should be only one or two simple rules for the pronunciation of single consonant morphemes, and there should be no exceptions to these rules.
The simplest way to implement these five considerations is surely to use the letters of the Roman alphabet as a syllabary, with each letter denoting the same syllable in all contexts. We shall, in effect, drop the use of letters as either vowels or consonants, which Dutton introduced in his 1936 revision. This may see like a return to Dutton's use of the Roman alphabet in his International Symbolic Script of 1935; I shall not, however, be using the letters to classify "all thoughts and objects ... in 26 groups".
If one is using the letters of the Roman alphabet as a syllabary, there is no reason to maintain the distinction between upper and lower case letters. One could use all 52 letters as separate symbols in a syllabary. But, as I found several years ago when we were using the abbreviations BrScA and BrScB for two developments of the briefscript project, mixing upper and lower case is not helpful when typing.
Indeed, one could also incorporate numeric symbols 0 ..9 as well as various other symbols such as + = \ | : * ^ % (which represent vowels in Lin). Thus one could have a syllabary of about 70 characters.
Although the SMS language does use some digits (1, 2, 4 and 8) and other characters, e.g. &, @, their use is restricted within certain contexts. If we incorporated numeric symbols in the Brx syllabary, we would have words which consisted just of such symbols which could also be read as a numbers (e.g. 537, say, could be read as "elephant" or as "five hundred [and] thirty seven"); this could cause ambiguity and would be confusing.
I had also considered using some Greek letters, e.g. π = /pi/, μ = /mi/ or /mu/, but decided this would add another complication for anyone using a standard keyboard. If the odd Greek letter, why not an odd Cyrillic letter or two? So in the end I have restricted myself mainly to the 26 symbols of the modern lower case Roman alphabet with, possibly a very few other characters for consonant codas which serve also as morpheme separators.
As I have shown on the 'BrScB & other Roman letter syllabaries' page, this is by no means a new idea. I was experimenting with such systems as far back as the late 1950s, and Fuishiki Okamoto did just this for his auxlang Babm [bɔ'ɑ:bɔmu].
As the letters are being used to denote whole syllables and not single sounds (i.e. vowel or consonant) in the normal way, one could disregard traditional values and just assign syllabic values in a (pseudo)random manner. It will help, however, to remember the values if, a far as possible, they have some relationship to their traditional usage. But even if we have some system behind the syllabic values, this will not always be easy. Even Okamoto, whose syllabary does not appear to be systematic, has some odd values, e.g. x = [ki] and j = [zi].
- 1.2 The sounds
- In Brx I endeavored to restricted myself to phonemes that most people in the world already know or can learn to pronounce easily, The vowels, therefore, were restricted
to just the three vowels of languages such as Classical Arabic, Inuktitut and Quechua, i.e. at the vertices of the vocalic triangle:
front central back high /i/ __________ /u/ \ / \ / mid \ / \ / low /a/As for the consonants, Frederick Bodmer wrote:
"A battery of consonants with very wide currency would not include more than nine items - l, m, n, r, together with a choice between the series p, t, f, k, s, and the series b, d, v, g, z. Even this would be a liberal allowance. The Japanese have no l."
[1944, "The Loom of Language", London, George Allen & Unwin Ltd].Brx does indeed make no distinction between l and r, nor between voiced and voiceless plosives and fricatives. It keeps Bodmer's three plosives p, t, k (or b, d, g) but retains only one fricative, the sibilant s (or z). It further simplifies Bodmer's inventory in that before /i/ both dental/alveolar sounds and velar sounds fall together as palatals. It does, however, add to its inventory of consonants the approximants /j/ and /w/, being the semivocalic equivalents of [i] and [u] respectively.
This gives us a simple but complete syllabary as I show in Section 2 below.
2. The Brx syllabary
Brx uses the 26 lower-case letters of the ISO basic Latin alphabet as a syllabary. The Brx names of the letters are identical with the IPA pronunciation given beneath each letter in the table of subsection 2.2. Thus a word is pronounced simply by reading off the names of the lower case letters (for upper case letters, see below). There are no exceptions.
- 2.1 The choice of symbols
- As I have confined myself to the 26 letters of the ISO basic Latin alphabet, this will necessitate unusual use of some of the letters. Indeed, no consonant letters can be used in their 'normal' way
as each letter represents a CV syllable. We can summarize their use thus:
- a, b, c, d, i, j, k, l, m, n, p, q, r, s, t, u, z
are related to their normal values in the International Phonetic Alphabet (IPA); where there are pairs which IPA uses to denote voiceless and voiced contrasts, the IPA voiceless symbol represent Ca syllables and their voiced counterparts represent Cu syllables. - e, o, x, y
have uses related to their values in several languages:
e [ja] - cf. Afrikaans ee in steek /stɪək/; the breaking of Archaic Irish [eː] to Scottish Gaelic [iə], of Vulgar Latin e to /e̯a/ in certain positions, and similar breaking of stressed or long /e/ in other languages;
o [wa] - cf. Afrikaans o in bote /'bʊətə/; the breaking of Archaic Irish [oː] to Scottish Gaelic [uə], of Vulgar Latin o to /o̯a/ in certain positions, and similar breaking of stressed or long /o/ in other languages;
x [çi] - x = /ʃ/ in Maltese, Portuguese and Catalan;
y [wi] - in Middle English name of the letter y was /wiː/ from its Old English name [yː]; in Latin it represented the sound /y/ and /yː/. For the shift of Old English [yː] to [wiː] it may be noted that Korean ㅟ has allophones /y/ and /wi/.
- f, g, h, v, w are noticeably different from their use in any language:
f, v which normally denote labiodental fricatives, are used for the labial plosive and labial nasal respectively before [i]; i.e. f = [pi], v = [mi];
g, h are used for the [ɲi] and [nu] respectively: g being suggested by the Italian use of gn = [ɲ], and h simply because its shape is a "modified n" (also Cyrillic н = /n/).
w is used for [mu] as w may be regarded as a variant of
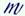 (mu ligature); also the use of v and w to fill the "missing" slots in the labial nasals is suggested by the
fact that in the Insular Celtic languages the lenition (or 'soft mutation') of /m/ is /v/ or /w/.
(mu ligature); also the use of v and w to fill the "missing" slots in the labial nasals is suggested by the
fact that in the Insular Celtic languages the lenition (or 'soft mutation') of /m/ is /v/ or /w/.
- a, b, c, d, i, j, k, l, m, n, p, q, r, s, t, u, z
- 2.2. Syllabary table
-
Note: the phonetic equivalents between [ ] are to be understood somewhat broadly. I have not given phonemic equivalents as [ci] is a falling together of /ti/ and /ki/, and to give [çi]
as /si/ and [[ɲi] as /ni/ might be misleading. Se also ' Notes on pronunciation' below.
high font
C+ilow central
C+ahigh back
C+uPlosives: labial f
[pi]p
[pa]b
[pu]dental/
alveolarc
[ci]t
[ta]d
[tu]velar k
[ka]q
[ku]Sibilants x
[çi]s
[sa]z
[su]Nasals: labial v
[mi]m
[ma]w
[mu]dental/
alveolarg
[ɲi]n
[na]h
[nu]Approximants: dental/alveolar
(may be lateral -
see note 2 below)i
[(j)i]r
[ɹa], [la]l
[ɹu], [lu]palatal e
[ja]j
[ju]onset glide a
[(ʕ)a]u
[(w)u]labio-velar y
[wi]o
[wa] - 2.3 Notes on pronunciation
-
- /i/ causes dental/alveolar and velar consonants to palatalize (a common feature in natural languages); hence in the plosive both /ti/ and /ki/ fall together as the same sound, which is shown below as [ci] which may be pronounced [ci], [ʨi] or [ʧi]. Likewise the palatal approximant may be pronounced as [çi], [ɕi], or [ʃi], and the palatal nasal maybe pronounced [ɲi], [nʲi] or [nji].
- The dental/alveolar approximant is [ɹ], but a lateral approximant [l] may be used or it may be realized as an alveolar tap [ɾ]; many languages, e.g. Japanese do not distinguish the sounds and Chinese has only [l] in syllable initial position. The sound may well tend towards [l] before [u] but [ɹ] before [a]. I shall henceforth represent the sound as [ɺ], a fusion of a rotated lowercase letter r with a letter l, thus [ɺa], [ɺu]; strictly this symbol is used in IPA to denote a voiced alveolar lateral flap, which could be a realization of this sound; but [ɺ] should be interpreted in the Brx pages more broadly to denote any of the sounds permitted in this note.
- /i/ and /u/ may be pronounced with or without the semivocalic onset glides (cf. those English dialects where, e.g., ear and year are homophones). The syllable a /a/, shown with a pharyngeal approximant [ʕ] onset, but may have glottal approximant [ɦ]; or it may have glottal stop [ʔ] onset, as could the syllables [i] and [u].
- The labial approximant may be realized as the labiodental approximant [ʋ].
- The initial consonant of the plosive and fricative series should normally be voiceless at the beginning of words; they may, however, be voiced within an utterance.
- Speakers of British English should be careful not to pronounce medial dental/alveolar consonants as [ʔ], and speakers of American English should not reduce a medial dental/alveolar to a flap (i.e. t and d should not be pronounced as r and l!).
- 2.4 Stress
- Words of two or more syllable are stressed on the first syllable, e.g.
- or ['waɺa] "human being, person, man [generic]";
- car ['ciʕaɺa] "city".
- 2.5 Upper case letters
- As we saw in 1.1 above, upper case letters do not form part of the syllabary. They have two uses in Brx:
- As the initial letter in a proper name; in this usage they are pronounced exactly the same way as the corresponding lower case letter, e.g.: Brx ['puɺuçi]; Jan ['juʕana] "John"; Eln ['jaɺana] "Helen".
- In Internationally used abbreviations. The abbreviation will have its own proper pronunciation.
- 2.6 Number of possible words
- If we restrict ourselves to morphemes of no more than three letters at the most, we find that the above syllabary gives us a maximum of:
After more than a century of use, Esperanto currently has some 9000 root words. The number of possible three syllable Brx words is way beyond that number.Words of one syllable: 26 Words of two syllables: 676 Words of three syllables: 17 576 TOTAL: 18 278
3. How morphemes are divided
Note: This Section was an outline of suggestions which might have been modified had the grammar of Brx been developed.
- 3.1. Introduction
- One of weaknesses of Speedwords was that the learner could be presented with words that could be analyzed in more than one way. We seek to avoid this by having self-segregating morphemes. Piashi did manage this, but at the expense of kludgey rules of vowel hiatus and a severe reduction in the possible number of words (e.g. just over 2000 three letter words).
- 3.2 Brx looks again at International Symbolic Script
- In Section 1.1 above we said that Brx was abandoning the use of separate letters for consonants and vowels, which Dutton introduced in the 1936 and all subsequent versions of
Speedwords, and reverting to the spirit of Dutton's International Symbolic Script (ISS) of 1935 in which any of the letters could be used in any position in a word. So did ISS also fail
to show morpheme division?
It is clear that Dutton, in fact, used the dot to denote division in compound words, e.g. in the excerpt from Shaw's "St Joan", given on the 'Speedwords is (largely) a relexification of English' page, we find: zt.hzs "fields", oy.ym "(to) chain", tg.ma "(to) climb".
We saw from examples given in Section 2.2 that Brx stresses the first syllable in a polysyllabic word; thus if the Brx words for the verbs "to chain" and "to climb" were the same compounds as in ISS, we would have oy.ym ['waju'juma] and tg.ma ['taɲi'maʕa] respectively, where in writing the morpheme boundary is shown by a dot and in speech by stressing the syllable following the dot. However, Brx will not be using compound words for those two concepts.
Also, it is apparent from the "St Joan" that Dutton did not show all morpheme boundaries, but only those between lexical (and, presumably, free) morphemes. The words zt.hzs "fields", hos "flowers", kps "feet" uqaqs "soldiers" and phps "hills" show that -s marks the plural. I assume that Dutton did not allow morphemes that ended in -s. However, this expedient will not do for Brx.
- 3.3 Brx may learn from ancient Egyptian and from Lin
- Brx may learn not from ancient hieroglyphic script (or even the hieratic and demotic scripts) of ancient Egypt, but from conventions used by Egyptologists when transcribing ancient
Egyptian. For example:
- ỉw ỉr.n=ỉ prt wp-wȝwt wḏȝ=f r nḏ ỉt=f
I conducted the procession of Wepwawet, when he set out to protect his father - ỉw ḳrs.n=ỉ ỉȝw, ḥbs.n=ỉ ḥȝy n ỉr=ỉ ỉwỉt r rmṯ
I buried the old, I clothed the naked, and I did no wrong against people
In the two examples above we find three different symbols used to mark morpheme boundaries: the dot (.) before a grammatical affix, hyphen (-) before a lexical morpheme, and equals sign (=) before a personal suffix (for those interested, a gloss of the two sentences is given in subsection 3.5 Appendix below). Similarly Brx may use different symbols before different types of morpheme, though these will not be identical to the above symbols
So what does Brx learn from Lin? In that language we find various symbols are given a pronunciation; e.g. = (equals sign) is pronounced [ã:], : (colon) pronounced [õ:] and * (asterisk) pronounced [ũ:].
Likewise, any separators will be reflected in pronunciation in Brx.
- ỉw ỉr.n=ỉ prt wp-wȝwt wḏȝ=f r nḏ ỉt=f
- 3.4 Brx morpheme dividers
- Brx similarly uses separators; it will possibly also, like Lin, use other symbols normally used for punctuation and, as in Lin, these will be reflected in the pronunciation; but the grammar is has
not been properly worked out, so this is on hold.
The following has been proposed but as the grammar is worked out, it is quite possible that this may be modified.
The use of these morpheme dividers would have been worked out as the grammar developed.Phoneme Pronunciation Symbol Ø
(null phoneme)The syllable has no coda but the syllable immediately after ( . ) will be stressed, i.e it marks the first syllable of the next morpheme. It cannot occur before a monosyllabic atonic morpheme .
(dot or period)
or white space/ŋ/ Syllable final /ŋ/, which may be pronounced [ɲ] after /i/, may optionally nasalize the preceding vowel thus: [ĩ], [ã] or [ũ].
It may also optionally be assimilated to [m] before /p/, and [n] before /t/.
Before sibilants and approximants it may be pronounced as [ŋ]/[ɲ] or just as vowel nasalization-
(dash)/r/ Syllable final /r/ may be pronounced as a trilled [r], or as a rhotic tap [ɾ] or [ɽ], or a rhotic approximate [ɹ] or [ɻ], or it may be pronounced as rhotacization of the preceding vowel, i.e [i˞], [a˞] or [u˞]. '
(vertical apostrophe) - 3.5 Appendix
- Glosses of the two Egyptian sentences in subsection 3.3 above:
- ỉw ỉr-n-ỉ prt wp-wȝ-wt wḏȝ-f r
AUX do-PST-1SG procession open-way-F.PL set.out-3SG toward(s)
nḏ ỉt-f
protect father-3SG - ỉw ḳrs-n-ỉ ỉȝw, ḥbs-n-ỉ ḥȝy n ỉr-ỉ ỉwỉt
AUX bury-PST-1SG old, clothe-PST-1SG naked NEG.PST do-1SG wrongdoing
r rmṯ
toward(s) people
Note:
- The preverbal auxiliary ỉw has no simple English equivalent. "It evokes a sense of involvement in the assessment or presentation of what is
said/written."
[Collier, M & Manley, W (1998), How to read Egyptian hieroglyphs, Eighth impression 2001, London: British Museum Press] - wp-wȝ.wt (= "the one who opens ways/roads") was a funerary deity who led souls alongs the paths of the dead. His name is variously anglicized as Wepwawet or Upuaut or the Greek Ὀϕῶις Ophôis (both hieroglyphic and hieratic script indicated only consonants or strings of consonants; modern renderings of the name are purely conventional).
- The two sentences above are taken from "How to read Egyptian hieroglyphs", op. cit..
- ỉw ỉr-n-ỉ prt wp-wȝ-wt wḏȝ-f r
Briefscript pages:
- Introduction
- 1951 Speedwords Dictionary (PDF file)
- Phonology and Orthographies
Content of this page:

|
Created August 2011. Last revision: Copyright © Ray Brown |